Transformer (BERT, GPT, TabNet)
If You Don’t Understand Transformers: see these 3D charts
Positional Encoding

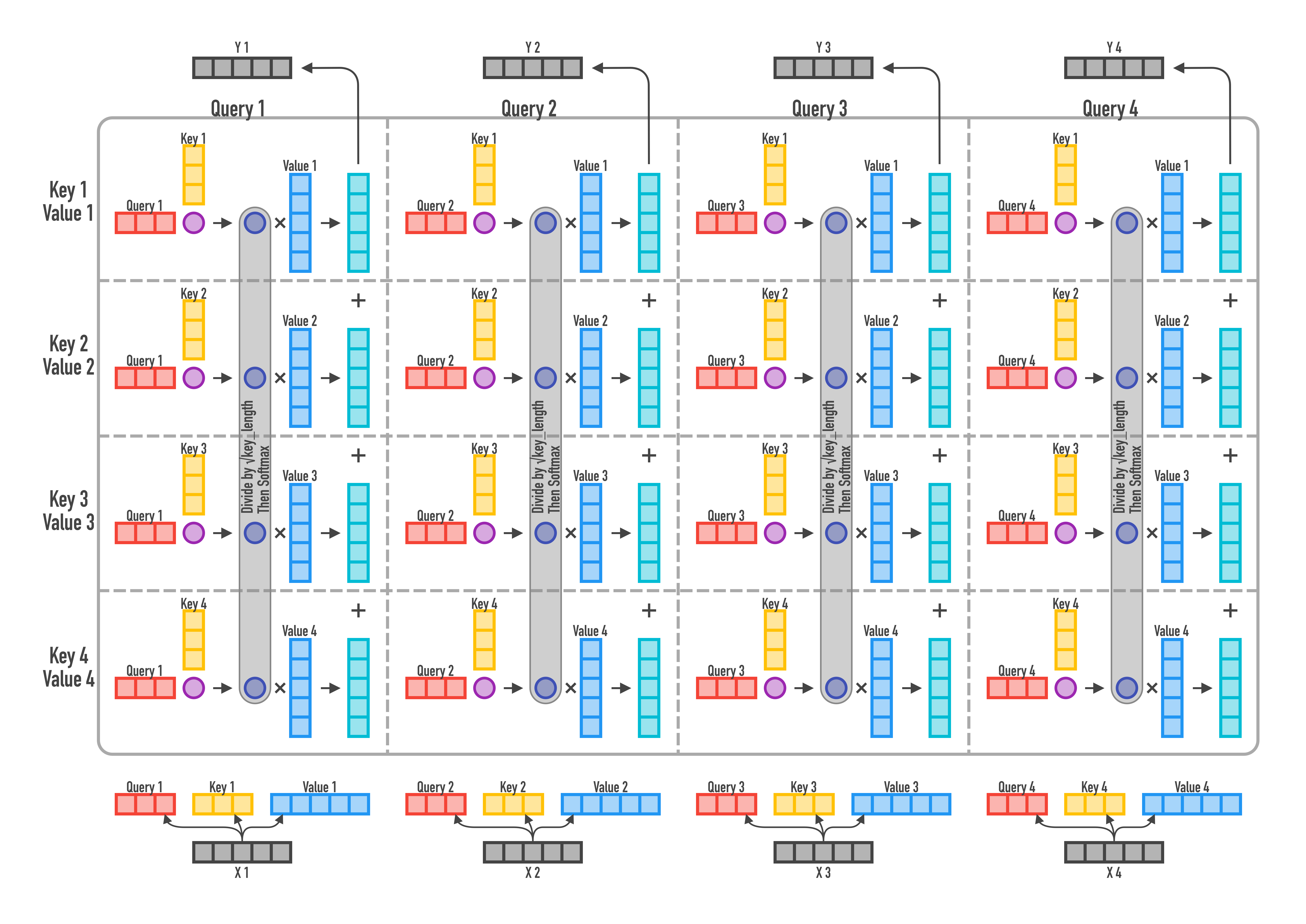
Dot-Product Attention
Additive Attention

Better initialization: T-Fixup
- Cosas que quitar que ya no hacen falta gracias a usar T-Fixup
- Learning Rate WarmUp (se puede entrenar con el LR maximo desde el principio)
- Capas LayerNorm
- La inicializacíon de los pesos es la siguiente:
- Gaussian initialization N(0,d^(-1/2)) for input embeddings where d is the embedding dimension.
- Xavier initialization for the rest of parameters:
- Scale embedding layer and decode parameters by (9N)^(-1/4)
- Scale encode parameters by (0.67 * N)^(-1/4)
for n,p in model.named_parameters():
if re.match(r'.*bias$|.*bn\.weight$|.*norm.*\.weight',n): continue
gain = 1.
if re.match(r'.*decoder.*',n):
gain = (9*H.trf_dec)**(-1./4.)
if re.match(f'.*in_proj_weight$',n): gain *= (2**0.5)
elif re.match(r'.*encoder.*',n):
gain = 0.67*(H.trf_enc**(-1./4.))
if re.match(f'.*in_proj_weight$',n): gain *= (2**0.5)
if re.match(r'^embeds|^tagembeds', n):
trunc_normal_(p.data,std=(4.5*(H.trf_enc+H.trf_dec))**(-1./4.)*H.trf_dim**(-0.5))
else:
nn.init.xavier_normal_(p,gain=gain)
Theory Reference
- The Illustrated Transformer (Jay Alammar)
- Towards Data Science: Transformers Explained Visually
Code Refernce
- Low Level code (from scratch): Useful for understand the transformer and make custom changes
- High Level code: Usful for quick use and train
- Simple PyTorch-Lightning Transformer Example with Greedy Decoding
- Solución de competición Riid de kaggle por Javier Martín y Andrés torrubia (Transformer en Pytorch con T-Fixup init)
- x-transformers por lucidrains